May 21, 202462 min readUpdated May 6, 2026
Unraveling the ChatGPT Mystery: Analyzing the Capabilities and Appeal of the Viral A.I.
ChatGPT, a groundbreaking language generation neural network, is revolutionizing the way we interact with machines. Delve into its architecture, training process, and diverse applications, exploring the potential of this
Demystifying the Inner Workings of ChatGPT
The impressive human-like text generation capabilities of ChatGPT have taken many by surprise. But how exactly does it accomplish this? In this article, I’ll provide a high-level look under the hood to shed light on ChatGPT's inner workings—and why it's so adept at producing meaningful output. I'll focus on the big picture ideas rather than technical intricacies. (And much of what I describe applies equally well to other leading language models.)
Fundamentally, ChatGPT is always trying to generate a “sensible continuation” of the text it's been given so far. “Sensible” here means “what a human might plausibly write next”, based on patterns gleaned from analyzing billions of webpages and books.
Consider the input "The best thing about AI is its ability to". ChatGPT essentially searches its vast training data, finds many real examples starting this way, and sees what words tend to follow. It produces a ranked list of likely next words, each with an associated probability.
But it doesn't look at literal text matches. Rather, it finds semantic equivalents and makes judgments based on meaning. Still, the end result is selecting the next word or words that would plausibly follow in a human-written text.

How ChatGPT Selects Each Next Word
The extraordinary thing is that when ChatGPT generates text like an essay, it essentially just repeatedly asks "given what's been written so far, what should the next word be?"—and adds that word. (More precisely, as I'll explain, it adds a "token", which could be part of a word, enabling it to sometimes "invent new words".)
At each step it gets a ranked list of possible next words with assigned probabilities. But how does it decide which to actually select and append? One might assume it would always pick the "top-ranked" word (with highest probability). But surprisingly, this produces rather "dull" and repetitive text. If instead it sometimes randomly chooses lower-ranked words, the result is more "interesting" and creative.
This element of randomness means that repeating the same prompt can yield different essays each time. And there's a particular "temperature" parameter that controls how often lower-ranked words get picked—with a value around 0.8 working well for essay writing. (Notably this is based on empirical evidence rather than theory. The physics-inspired name "temperature" is just because exponential distributions are used, not due to any actual physical connection—that we know of so far.)
For clarity, I'll mostly illustrate concepts using a simplified GPT-2 model small enough to run on a desktop, rather than the full ChatGPT. This lets me provide executable Wolfram Language code with each example that you can immediately run yourself. (Click any picture to copy its code.)
For instance, here's how to get the probability table above.
First we retrieve the underlying "language model" neural net:

We'll dig into the internals of this neural network later and discuss its operation. But for now we can treat the "net model" like a black box, input our existing text, and ask it to return the 5 words with the highest probabilities of appearing next according to the model:

This takes the list of next words with probabilities and converts it into a structured "dataset" for easy analysis:

Here is the process when repeatedly "applying the model"—at each step adding the word that has the highest probability (specified in the code as the "decision" from the model):

What happens if we continue generating text for longer? In this "zero temperature" case where the top probability word is always picked, the output soon becomes confused and repetitive:

What happens if we continue generating text for longer? In this "zero temperature" case where the top probability word is always picked, the output soon becomes confused and repetitive:

And each time this process runs, different random choices will be made, resulting in different text outputs every time—as shown in these 5 examples:

It's notable that even for the very first word there are many possible "next word" options to pick from (at temperature 0.8), though their probabilities diminish rapidly (and yes, the straight line on this log-log plot indicates an n-1 "power-law" decay very typical of language statistics overall):

So what happens if we continue generating text for an extended length? Here's a random example. It's improved from the zero temperature case, but still comes out rather odd:

The previous example used the basic GPT-2 model from 2019. With newer and larger GPT-3 models, the text quality is improved. Here's the zero temperature text from the same prompt, but using the largest GPT-3 model:

And this is a random example at temperature 0.8:

How Are Next Word Probabilities Determined?
Alright, so ChatGPT always selects the next word probabilistically. But how are these probabilities derived in the first place? Let's start with a more basic case of generating text one letter at a time. How can we determine the probability distribution over letters?
A very simple approach is to take a sample of English text and count letter frequencies. For example, we can analyze the Wikipedia article on "cats" to tally up letter occurrences:

And we can follow the same process to count letter frequencies in the Wikipedia article on "dogs":

The letter counts are comparable between the two articles, but not identical - "o" is predictably more common in the "dogs" text since that word itself contains an o. However, if we analyzed a sufficiently large and diverse sample of English writing, we'd expect the letter frequency results to stabilize and become fairly consistent:

This shows example text produced by randomly generating a sequence of letters based on the learned probabilities:

We can segment this by inserting spaces, treating them like characters, with a specific likelihood.

We can improve the process of creating "words" by aligning the distribution of "word lengths" with the patterns found in English.

We haven't generated any "real words" in this instance, but there is some improvement in the results. To enhance the process, we must go beyond random letter selection. For instance, we are aware that when we have a "q," the following letter is almost always "u."
Here's a graphical representation of letter probabilities when considered individually:

Here's a chart illustrating the likelihood of letter pairs, known as "2-grams," in standard English text. The chart displays potential first letters horizontally and second letters vertically.

Here, we observe that the column for "q" is devoid of content (zero probability) except in the row for "u." So, instead of constructing our "words" one letter at a time, let's create them by considering two letters at a time, utilizing these "2-gram" probabilities. Here's a sample of the outcome, which happens to feature a few "real words."
.png)
By having a substantial amount of English text, we can achieve accurate estimations for not only single letter probabilities or pairs of letters (2-grams) but also for extended sequences of letters. When we create "random words" using increasingly longer n-gram probabilities, we notice that they become increasingly "more plausible" as they incorporate longer sequences.

However, let's consider a different scenario, much like ChatGPT does. In this scenario, we work with complete words, not individual letters. English boasts approximately 40,000 commonly used words. By analyzing an extensive collection of English text, encompassing, for instance, millions of books and hundreds of billions of words, we can gauge the frequency of each word. Using this information, we can initiate the creation of "sentences." In these sentences, each word is chosen independently and at random, with a probability linked to its occurrence in the corpus. Here's an example of the results:
.png)
Unsurprisingly, the output lacks coherence. So, how can we improve the quality? Similar to our approach with individual letters, we can begin to consider not only the probabilities of single words but also the probabilities of word pairs or longer word sequences. When focusing on word pairs, here are five examples of the results, all originating from the word "cat."

It's becoming somewhat more "coherent." One might envision that with the use of sufficiently lengthy n-grams, we could essentially achieve something akin to a ChatGPT—a system capable of generating extended sequences of words with "appropriate overall probabilities" for essay-like content. However, a significant challenge arises: there's far from enough English text available to deduce these probabilities.
In a comprehensive web crawl, there might be around a few hundred billion words, and digitized books could contribute another hundred billion words. Nevertheless, with a pool of 40,000 common words, even the number of possible 2-grams reaches a staggering 1.6 billion, and 3-grams expand to an astronomical 60 trillion. Therefore, estimating probabilities for all of these sequences from existing text is infeasible. As we extend to "essay fragments" comprising 20 words, the possibilities surpass the total number of particles in the universe. Essentially, it's impractical to enumerate them all.
So, what's the solution? The key concept revolves around constructing a model that allows us to estimate the probabilities of sequences, even if we've never explicitly encountered those specific sequences within the text corpus we've analyzed. At the heart of ChatGPT lies what we call a "large language model" (LLM) that excels at precisely this task.
What Is a Model?
Imagine you want to determine, as Galileo did in the late 1500s, how long it takes for a cannonball dropped from various heights of the Tower of Pisa to reach the ground. One approach is to measure each case and compile a table of results. Alternatively, you can embrace the essence of theoretical science: crafting a model that provides a method for computing the answer, rather than solely relying on measurements for each scenario.
Let's consider that we possess somewhat idealized data regarding the time it takes for the cannonball to fall from different tower heights:

How can we determine the time it will take for the fall from a floor for which we lack explicit data? In this scenario, we can rely on established principles of physics to calculate it. However, if we only possess the data and are uncertain about the governing laws behind it, we may resort to making a mathematical conjecture. For example, we might speculate that using a linear model is appropriate:

We have the option to select various straight lines, but the one presented is the one that, on average, closely aligns with the provided data. Using this particular straight line, we can estimate the falling time for any floor.
How did we arrive at the idea of using a straight line in this context? In essence, it wasn't a foregone conclusion. It's a choice grounded in mathematical simplicity, as we often find that many datasets can be effectively represented by straightforward mathematical models. We could opt for a more intricate mathematical approach, such as a + b x + c x^2, and in this case, we achieve improved accuracy:

However, things can take a turn for the worse. For instance, here's the most optimal result we can achieve using a + b/x + c sin(x):

It's essential to recognize that there is always an underlying structure in any model you use. This structure consists of a specific set of "adjustable parameters" or "knobs" that can be configured to fit your data. In the case of ChatGPT, there are numerous such "knobs" in use, actually numbering 175 billion.
However, what's truly remarkable is that the fundamental structure of ChatGPT, encompassing "just" that many parameters, is adequate to create a model that calculates next-word probabilities with sufficient accuracy to produce coherent and reasonably lengthy textual content.
Models for Tasks Resembling Human CapabilitiesThe previous example focused on developing a model for numerical data originating from basic physics, where it's well-established that "simple mathematics applies." Yet, in the case of ChatGPT, our aim is to create a model for human language text generated by human minds. However, for a task like this, we don't currently possess anything resembling "simple mathematics." So, what would a model for this purpose look like?
Before delving into the domain of language, let's explore another human-like task: image recognition. As a straightforward illustration, let's consider recognizing images of digits (a classic machine learning example):

One approach we could take is to collect a set of sample images for each numeral:

To determine if an input image corresponds to a specific digit, one straightforward method is to conduct a direct, pixel-by-pixel comparison with our existing samples. However, as humans, we appear to employ a more sophisticated approach. We can recognize digits even when they are handwritten, subject to various alterations and distortions, suggesting a higher-level cognitive process at work.

When we designed a model for our numerical data previously, we could take an input numerical value 'x' and compute 'a + b x' with specific values for 'a' and 'b.' In a similar vein, for this case, if we consider the gray-level value of each pixel as a variable 'xi,' can we find a function that, when assessed, reveals the digit depicted in the image? It is indeed feasible to devise such a function. However, it's important to note that this function is not particularly straightforward and often involves hundreds of thousands of mathematical operations.
The end outcome, though, is that if we input the array of pixel values from an image into this function, it will provide us with a numerical output specifying the digit represented in the image. We will discuss the construction of this function and delve into the concept of neural networks later. For now, let's treat this function as a "black box" that takes input images, such as arrays of pixel values for handwritten digits, and produces the corresponding numerical digit as the output.

So, what's the underlying process in play here? Let's consider the scenario where we gradually blur a digit. For a little while our function still “recognizes” it, here as a “2”. But soon it “loses it”, and starts giving the “wrong” result:

But why do we say it’s the “wrong” result? In this case, we know we got all the images by blurring a “2”. However, if our objective is to create a model of how humans perceive and recognize images, the crucial question to ask is how a human would react when presented with one of these blurred images, unaware of their origin.
We consider our model "effective" when the results produced by our function consistently align with what a human observer would conclude. The notable scientific fact is that, for image recognition tasks of this nature, we have now gained substantial understanding of how to construct functions that achieve this alignment.
Can we "mathematically prove" that these functions work? No, because to do so, we would need a comprehensive mathematical theory describing human perception. For instance, if we take the "2" image and alter a few pixels, determining whether the image should still be classified as a "2" depends on the intricacies of human visual perception. Furthermore, this answer may vary for other creatures like bees or octopuses and could be entirely different for potential extraterrestrial beings.
Neural Networks
So, how do our standard models for image recognition tasks operate? The prevailing and highly successful method relies on neural networks. Neural networks, with a form closely resembling their contemporary usage, were initially conceived in the 1940s. They can be considered as simplified models of how human brains function.
In the human brain, approximately 100 billion neurons (nerve cells) exist, and each has the capability of generating electrical impulses up to around a thousand times per second. These neurons are interconnected in a complex network, with each neuron possessing branching connections that enable the transmission of electrical signals to potentially thousands of other neurons. In a rough approximation, the occurrence of an electrical pulse in a given neuron at a specific moment depends on the input pulses it has received from other neurons, with each connection contributing differently.
When we "perceive an image," it involves photoreceptor cells at the back of our eyes detecting photons of light from the image and generating electrical signals in nerve cells. These nerve cells are interconnected with others, and the signals pass through a series of neural layers. It's within this process that we "recognize" the image and eventually "form the thought" that we are "seeing a 2," possibly leading to verbalizing the word "two."
The "black-box" function described in the previous section is a mathematical representation of such a neural network. This particular function comprises 11 layers, with 4 "core layers":

This neural network doesn't have a particularly "theoretically derived" foundation; it was essentially engineered in 1998 and proved to be effective. (In a sense, this mirrors the description of our brains, which are products of biological evolution.)
Now, how does a neural network of this kind accomplish "recognition"? The pivotal concept behind this is the idea of attractors. Let's consider a set of handwritten images featuring the digits 1 and 2:

Our goal is to gather all the images of "1's" into one distinct category and all the images of "2's" into another. To put it differently, if an image is closer to being a "1" than a "2," we want it to be categorized as a "1," and vice versa.
To illustrate this concept, imagine we have specific locations in a two-dimensional plane, represented as dots (in a practical scenario, they might be positions of coffee shops). In this analogy, we envision that regardless of our starting point on the plane, we would always gravitate towards the nearest dot, effectively choosing the closest coffee shop. This can be depicted by dividing the plane into distinct regions, often referred to as "attractor basins," separated by abstracted "watersheds."

We can view this as implementing a form of "recognition task" where our goal isn't to identify which digit an image most closely resembles. Instead, we're directly determining which dot a given point on the plane is nearest to. (The setup we're illustrating here with the "Voronoi diagram" separates points in a two-dimensional Euclidean space, and the digit recognition task can be seen as performing something quite analogous but in a 784-dimensional space derived from the gray levels of all the pixels in each image.)
Now, how do we instruct a neural network to perform a recognition task? Let's consider this straightforward example:

Our objective is to accept an "input" represented by a position {x, y} and then identify it as being the closest to one of the three points. In simpler terms, we intend for the neural network to calculate a function of {x, y} as follows:

How can we achieve this using a neural network? At its core, a neural network consists of interconnected, simplified "neurons," typically organized in layers. A basic example can be illustrated as follows:
.png)
Each "neuron" is essentially designed to compute a straightforward numerical function. When we want to utilize the network, we input numerical values, such as our coordinates x and y, at the top layer. Then, the neurons within each layer proceed to "compute their functions" and transmit the outcomes forward through the network, culminating in the final result at the bottom:

In the conventional (biologically-inspired) configuration, each neuron is equipped with a specific set of "incoming connections" originating from neurons in the preceding layer. Each connection is associated with a particular "weight," which can be a positive or negative numerical value. The value of an individual neuron is determined by multiplying the values of the "previous neurons" by their respective weights, summing these products, adding a constant term, and subsequently applying a "thresholding" or "activation" function. In mathematical terms, if a neuron has inputs represented as x = {x1, x2 …}, we compute f[w . x + b], where the weights w and the constant term b are typically unique for each neuron in the network. The function f is generally uniform across neurons.
The calculation of w . x + b is essentially a process of matrix multiplication and addition. The "activation function" f introduces nonlinearity, which ultimately results in complex behavior. Various activation functions are commonly employed, and for this discussion, we will use the Ramp (or ReLU) activation function.

For every task we wish the neural network to execute, or alternatively, for each overarching function we need it to assess, we will have distinct weight choices. (We will explore this further in subsequent discussions, where these weights are typically established through "training" the neural network using machine learning with examples of the desired outputs.)
In essence, each neural network corresponds to an overarching mathematical function, even though expressing it explicitly can be intricate. For the provided example, this function would be:

The neural network within ChatGPT can also be described as a mathematical function, albeit one with billions of terms.
Now, returning to the individual neurons, here are some illustrations of the functions that a neuron with two inputs (representing coordinates x and y) can calculate, based on different selections of weights and constants, and using the Ramp as the activation function:
.png)
But when it comes to the larger network mentioned earlier, here's what it calculates:

It's not an exact match, but it closely resembles the "closest point" function we previously demonstrated.
Now, let's explore the outcomes with various other neural networks. In each instance, as we'll elaborate on later, we employ machine learning to determine the most suitable weight configurations. Subsequently, we display the computations performed by the neural network using those specific weights:

Larger networks generally excel in approximating the desired function. Typically, in the central regions of each attractor basin, we achieve the exact outcome we desire. However, at the boundaries—where the neural network encounters difficulty in making definitive decisions—matters can become more complex.
In this straightforward mathematical-style "recognition task," it's evident what constitutes the "correct answer." However, in the context of recognizing handwritten digits, the situation is less straightforward. What if someone's handwritten "2" so closely resembles a "7," for instance? Nevertheless, we can investigate how a neural network distinguishes between digits, providing some insights:

Can we express the network's differentiation process in a strictly mathematical manner? Not quite. It essentially follows the inherent operations of the neural network. However, it frequently aligns quite closely with the distinctions made by humans.
To delve into a more intricate scenario, consider having images of cats and dogs. Suppose there's a neural network that has undergone training to differentiate between them. Here's what it might achieve when presented with certain examples:

Now, the "correct answer" becomes even less clear. What if you encounter a dog cleverly disguised as a cat, for example? In any case, the neural network will produce a response based on the input it receives, and this response typically aligns reasonably well with human judgment. As mentioned earlier, this isn't a fact that can be "derived from first principles." It's an empirical finding, at least within certain domains. Nonetheless, it's a fundamental reason why neural networks are valuable – they, in some way, replicate a "human-like" approach to problem-solving.
When you view a picture of a cat and ponder, "Why is that a cat?" you might begin to mention features like "I see its pointy ears," among others. However, articulating precisely how you recognized the image as a cat is often challenging. It's a process your brain somehow undertakes, yet there isn't currently a way to dissect how the brain arrived at that conclusion (at least not yet). How about an artificial neural network? Well, it's relatively straightforward to observe the actions of each "neuron" when presented with a cat image. However, even achieving a rudimentary visualization is frequently quite challenging.
In the final network used for the "nearest point" problem mentioned earlier, there are 17 neurons. For the network tasked with recognizing handwritten digits, there are 2,190 neurons. In the network employed for identifying cats and dogs, there are 60,650 neurons. Visualizing a 60,650-dimensional space can be quite challenging. However, given that this network is designed for processing images, many of its layers of neurons are structured into arrays, akin to the arrays of pixels in the images it analyzes.
If we consider a typical cat image:

In this scenario, we can depict the conditions of the neurons in the initial layer using a set of generated images, several of which can be easily understood as elements like "the cat without its background" or "the cat's silhouette":

By the time we reach the 10th layer, it becomes more challenging to discern the underlying processes:

However, we can generally assert that the neural network is identifying specific characteristics (possibly including features like pointy ears) and using these to determine the content of the image. But are these features those that can be explicitly named, such as "pointy ears"? In most cases, they are not.
As for whether our brains employ similar features, this remains mostly uncertain. Nevertheless, it is worth noting that the initial layers of a neural network, like the one illustrated here, appear to identify aspects of images (such as object edges) that parallel the features detected by the first stage of visual processing in the human brain.
Now, let's say we desire a "theory of cat recognition" within neural networks. We could state: "Look, this particular network accomplishes it," and this provides us with a sense of how challenging the problem is (including the required number of neurons or layers). However, as of now, we lack a means to provide a "narrative description" of what the network is truly doing. This might be due to computational irreducibility, implying there is no general way to ascertain its processes without explicitly tracing each step. Alternatively, it may result from our incomplete understanding of the underlying scientific principles that could enable us to summarize these operations.
We will confront similar challenges when we delve into the realm of generating language with ChatGPT. Once again, it remains uncertain whether we can succinctly "summarize its operations." However, the richness and intricacy of language, coupled with our familiarity with it, might offer more promising avenues for exploration.
Machine Learning and Neural Network Training
Up to this point, our discussions have revolved around neural networks that are already equipped to perform specific tasks. However, what renders neural networks highly valuable (presumably in brains as well) is their capacity not only to potentially handle a wide array of tasks but also to undergo incremental "training from examples" in order to carry out those tasks.
When we construct a neural network to distinguish between cats and dogs, we don't need to explicitly program it to detect features like whiskers, for instance. Instead, we present numerous examples of cats and dogs and allow the network to "learn" from these examples how to differentiate between the two.
The key concept here is that the trained network possesses the ability to "generalize" from the specific examples it has encountered. As we've observed earlier, it doesn't merely recognize the pixel pattern of a given cat image it was shown; rather, it somehow distinguishes images based on a form of "general catness" that it has learned.
So, how does the training of neural networks actually function? Fundamentally, our objective is always to identify weight configurations that enable the neural network to effectively replicate the provided examples. Subsequently, we rely on the neural network to "interpolate" or "generalize" between these examples in a manner that is deemed "reasonable."
Let's consider a problem even simpler than the nearest-point example mentioned earlier. Let's attempt to teach a neural network to learn the function:

To accomplish this task, we require a network with a single input and a single output, depicted as follows:

However, the question remains: which weights and parameters should we employ? For every conceivable combination of weights, the neural network will produce a certain function. To illustrate, here's what it produces with a selection of randomly chosen weight sets:
.png)
Indeed, it's evident that none of these instances come remotely close to replicating the desired function. So, how do we go about determining the weights necessary to replicate the function?
The fundamental concept involves providing a substantial number of "input → output" instances to "learn from" and subsequently attempting to identify weights that can replicate these instances. The following illustrates the outcome as we incrementally incorporate more examples:

During each phase of this "training" process, the weights within the network are continually fine-tuned, and we observe that eventually, we achieve a network that accurately reproduces the desired function. So, how do we go about adjusting these weights? The fundamental concept is to assess, at each stage, "how distant we are" from attaining the desired function and then modify the weights in a manner that brings us closer.
To determine "how distant we are," we calculate what is often referred to as a "loss function" (or sometimes a "cost function"). In this instance, we employ a basic (L2) loss function, which calculates the sum of the squares of the disparities between the obtained values and the actual values. As our training process unfolds, we observe that the loss function gradually diminishes (following a distinct "learning curve" for various tasks) until we reach a point where the network effectively replicates the desired function, at least to a significant extent:

Now, let's delve into the final crucial piece, which is elucidating how the weights are modified to diminish the loss function. As mentioned before, the loss function provides a measure of the "gap" between the obtained values and the true values. However, the "obtained values" are determined at each stage by the existing configuration of the neural network and the weights within it. But consider this: if we treat the weights as variables, denoted as wi, we need to ascertain how to adapt these variables to minimize the loss that relies on them.
For instance, envision (in a highly simplified representation of common neural networks employed in practice) that we are dealing with only two weights, w1 and w2. In such a scenario, our loss function, as a function of w1 and w2, may exhibit the following behavior:

Numerical analysis offers a range of methods for identifying the minimum in situations of this nature. However, a common strategy is to systematically trace the trajectory of the steepest descent from the previous values of w1 and w2:

Similar to the flow of water down a mountain, this process guarantees that it will eventually reach a local minimum on the surface, much like a mountain lake. However, there's no assurance it will reach the global minimum, the absolute lowest point on the surface.
Determining the path of steepest descent on the "weight landscape" might not seem straightforward, but calculus comes to the rescue. As we mentioned earlier, a neural net can be viewed as a mathematical function that depends on its inputs and weights. By differentiating with respect to these weights, the chain rule of calculus allows us to deconstruct the operations carried out by successive layers in the neural net. This, in effect, enables us to reverse the operation of the neural net, at least within a local approximation, and progressively find weights that minimize the associated loss.
The image above illustrates the type of minimization required, even in the extremely simplified case of just two weights. However, it's worth noting that even with a much larger number of weights (such as the 175 billion used in ChatGPT), it is still possible to perform the minimization to some degree of approximation. In fact, a significant breakthrough in "deep learning" around 2011 was associated with the insight that, in some sense, it can be easier to achieve (at least approximate) minimization when dealing with a large number of weights compared to situations with relatively few weights.
Paradoxically, it can be easier to solve more complex problems with neural nets than simpler ones. The rough explanation for this lies in the fact that having many "weight variables" results in a high-dimensional space with numerous different directions leading to the minimum. In contrast, with fewer variables, it is easier to become trapped in a local minimum (resembling a "mountain lake") from which there is no clear path to escape.
It's important to note that in typical scenarios, there are multiple sets of weights that can yield neural nets with nearly identical performance. Furthermore, practical neural net training involves many random choices that lead to "different but equivalent solutions," as exemplified by the variations shown below.

However, every one of these "distinct solutions" will exhibit slightly varying behaviors. When we inquire about extrapolating beyond the region where training examples were provided, we may observe significantly divergent outcomes:

However, determining which of these solutions is the "correct" one remains elusive. They are all "consistent with the observed data," yet they represent different innate approaches to reasoning "outside the box," with varying degrees of human intuitiveness.
The art of training neural networks has seen significant advancements in recent years, largely driven by practical experience and experimentation. While some techniques have scientific underpinnings, much of the progress stems from accumulated knowledge and insights gained through trial and error.
Several essential components contribute to the successful training of neural networks. These components include selecting the appropriate network architecture for a given task, obtaining relevant training data, and leveraging pre-trained networks to enhance the training process. Surprisingly, a single network architecture can often generalize well across diverse tasks. This reflects the capacity of neural networks to capture general human-like processes, rather than task-specific details.
Historically, there was a tendency to minimize the functions that neural networks were required to perform. For example, in speech-to-text conversion, it was believed that the audio data should be pre-processed into phonemes before training. However, for human-like tasks, training the neural network directly on the end-to-end problem, allowing it to discover intermediate features and encodings, has proven to be more effective.
Another past practice involved adding complex individual components to neural networks to explicitly implement algorithmic ideas. However, it has become evident that employing simple components and allowing the network to self-organize, even in ways not entirely understood, often achieves equivalent results. Neural networks, like computers in general, primarily process data, typically presented as arrays of numbers. These arrays can be restructured and reshaped throughout the processing, such as in the digit identification network used earlier:

Now, how does one determine the appropriate size of a neural network for a specific task? It's somewhat of an art rather than a precise science. The key factor is understanding the task's complexity. However, estimating the difficulty of human-like tasks is inherently challenging. While there may be systematic methods to solve tasks mechanically with a computer, it's uncertain whether there are tricks or shortcuts that make human-like performance vastly easier. While a certain game might require exhaustive enumeration of a large game tree for mechanical play, there could be a more heuristic approach that achieves human-level performance with far less effort.
In cases involving small neural networks and simple tasks, it may become evident that reaching human-like performance is unattainable. For example, consider the best results achieved with small neural networks on the task described in the previous section:

So, what happens when a neural network is too small? It struggles to reproduce the desired function. However, when the network reaches a sufficient size and is trained with an adequate number of examples over a sufficient duration, it handles the task with ease. One noteworthy insight from the neural net community is that a smaller network can sometimes suffice if there's a "squeeze" in the middle that forces information to pass through a smaller intermediate layer. (It's worth noting that "no-intermediate-layer" or perceptron networks can only learn linear functions. However, with even one intermediate layer, it's theoretically possible to approximate any function, provided there are enough neurons. To make it practically trainable, some form of regularization or normalization is typically applied.)
Having determined an appropriate neural network architecture, the next step is obtaining the required training data, which often presents practical challenges. In supervised learning, explicit examples of inputs and corresponding expected outputs are needed. For instance, images may need to be labeled with their contents. While manual tagging is a labor-intensive process, there are opportunities to leverage existing data or use it as a proxy. Existing alt tags for web images or closed captions for videos can be useful. In cases like language translation, parallel versions of documents in different languages can be employed for training.
Estimating the amount of data required for training isn't straightforward. Transfer learning, which involves importing knowledge from another network, can significantly reduce data requirements. However, neural networks generally perform best when exposed to a large volume of examples. For certain tasks, repetitive examples are beneficial, with neural networks learning more effectively when continuously reminded of specific examples. This approach is similar to the role of repetition in human memorization.
Repetition alone may not suffice; neural networks also benefit from variations of the examples. These data augmentations don't need to be sophisticated; basic image processing can make images almost as valuable as new ones for training. When there's a shortage of real-world data, self-driving car training can utilize data from simulated environments resembling video games but lacking the complexity of real-world scenes.
For a model like ChatGPT, which performs unsupervised learning, obtaining training examples is simpler. ChatGPT's core task is to continue provided text, making it possible to generate training examples by masking out the end of a text passage and using the masked portion as input, with the goal of generating the unmasked text as output. This process doesn't require explicit tagging.
The learning process in a neural network revolves around finding the optimal weights to capture the provided training examples. Various choices and hyperparameter settings influence how this is accomplished. These include the selection of loss functions (e.g., sum of squares, sum of absolute values), methods for loss minimization (e.g., step size in weight space), and determining the size of the training batch. Machine learning can be applied to automate these decisions and set hyperparameters. Throughout training, the loss consistently decreases, as shown in this example using Wolfram Language:

In typical neural network training, it's common to observe the loss decreasing initially, but eventually, it stabilizes at a constant value. The success of the training is often judged by the final loss value, and if it's sufficiently small, the training is considered effective. If the loss remains large, it may be a signal to consider altering the network architecture.
Estimating the duration required for the learning curve to stabilize is challenging, as it depends on factors like the neural network's size and the volume of data used. Training neural networks is computationally intensive, with the majority of the effort involving operations on arrays of numbers, a task well-suited for GPUs. Consequently, the availability of GPUs typically limits neural network training.
Looking ahead, it's highly probable that more effective methods for training neural networks or accomplishing tasks akin to those handled by neural networks will emerge. Neural networks' fundamental concept involves constructing a versatile "computing fabric" from numerous simple, essentially identical components, which can be incrementally adjusted to learn from examples. Presently, this adaptation primarily relies on calculus applied to real numbers, but there's a growing realization that high-precision numbers may not be necessary, and even 8 bits or less could be adequate with current methods.
For computational systems like cellular automata, which operate in parallel on individual bits, the approach to incremental modification remains uncertain, although there's no inherent reason it couldn't be achieved. In fact, much like the "deep-learning breakthrough of 2012," incremental modification may prove more manageable in complex scenarios than in simpler ones.
Neural networks, somewhat akin to brains, feature a relatively fixed network of neurons, with the modification focused on the strength (or "weight") of connections between them. While this setup aligns with biology, it's unclear whether it's the optimal approach to achieving the functionality we require. A system involving progressive network rewriting, akin to our Physics Project, might offer superior results.
However, a significant limitation within the current framework of neural networks is the fundamentally sequential nature of neural net training. The effects of each batch of examples are sequentially propagated back to update the weights. Current computer hardware, even when incorporating GPUs, often leaves most of the neural network idle during training, updating only one part at a time. This limitation is partly due to the separation of memory from CPUs (or GPUs) in today's computers. In contrast, the brain likely operates differently, with each "memory element" (i.e., neuron) serving as a potential active computational unit. Future computer hardware configured in a similar manner might enable more efficient training.
While the capabilities of models like ChatGPT may seem remarkable, the idea that continuously increasing the size of neural networks will enable them to perform "everything" has limitations. For tasks within the realm of immediate human comprehension, this approach may work, but the lessons from centuries of science show that certain tasks, particularly in nontrivial mathematics and computation, involve computational irreducibility. This means that some computations cannot be significantly simplified and require tracking each computational step in detail.

The typical tasks we perform with our brains are likely intentionally chosen to avoid computational irreducibility. Mental math, for example, requires special effort, and comprehending the operation of a nontrivial program solely within one's mind is nearly impossible in practice.
For these challenges, we have computers. Computers excel at handling long, computationally irreducible tasks. Importantly, there are generally no shortcuts for these tasks. While one can memorize specific examples or recognize computationally reducible patterns, computational irreducibility means that unexpected outcomes may occur. The only way to truly determine the results in specific cases is to explicitly perform the computation.
A fundamental tradeoff exists between a system's capability and its trainability. Systems capable of utilizing their computational abilities effectively often exhibit computational irreducibility and are less trainable. Conversely, highly trainable systems may lack the capacity for complex computation.
In the case of ChatGPT, its neural network primarily functions as a "feed-forward" network, lacking the capability to perform nontrivial computations with complex "control flow."
Historically, irreducible computations were not a significant concern, but in our modern technological world, mathematics and general computations are vital. Natural systems often involve irreducible computation, and we are gradually learning to emulate and utilize it for technological purposes.
While neural networks can identify regularities similar to those recognized by human thinking, they struggle with tasks in the domains of mathematical and computational science. To tackle such tasks, they need to utilize an "ordinary" computational system as a tool.
It's important to note that the success of ChatGPT and similar models in tasks previously considered too difficult for computers does not imply that computers have fundamentally advanced beyond their computational capabilities. Instead, these tasks are computationally shallower than initially believed.
In essence, this brings us closer to understanding how humans manage tasks like writing essays or working with language, revealing that such tasks are computationally less complex than previously assumed.
With a sufficiently large neural network, it might match human capabilities in various areas. However, it still wouldn't capture the full extent of what the natural world or the tools derived from it can achieve. These tools, both practical and conceptual, have expanded human understanding and harnessed more of the physical and computational universe.
The Concept of Embeddings
Neural networks, as currently structured, rely on numerical data. To apply them to tasks involving text, we must find a way to represent text using numbers. While we could start by assigning a unique number to each word in a dictionary, a more powerful idea emerges, known as "embeddings." Embeddings aim to represent the "essence" of something using an array of numbers, ensuring that similar concepts are represented by nearby numbers.
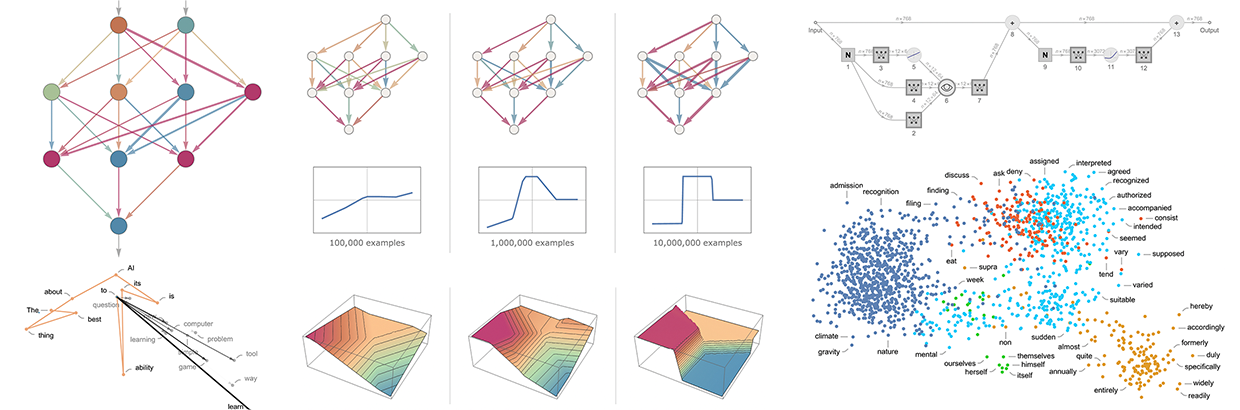
For instance, a word embedding attempts to position words in a "meaning space" where words with similar meanings are represented by neighboring numbers. While actual embeddings consist of large numerical lists, we can illustrate word embeddings by projecting them onto a 2D space, showing the proximity of words in the embedding.

Indeed, what we observe performs remarkably well in capturing everyday impressions. However, the question arises: How can we create such an embedding? The general approach is to analyze vast amounts of text, such as 5 billion words from the web, to determine the "similarity" in the contexts where different words appear. For instance, the words "alligator" and "crocodile" often appear interchangeably in similar sentences, placing them near each other in the embedding. Conversely, "turnip" and "eagle" rarely appear in similar contexts, causing them to be positioned far apart in the embedding.
But how can we practically implement this using neural networks? Let's begin by discussing embeddings not for words but for images. We aim to represent images with numerical lists in a way that assigns similar images similar numerical representations.
To determine if we should consider two images as similar, we might use a specific criterion. For instance, when dealing with images of handwritten digits, we would consider two images similar if they represent the same digit. Earlier, we introduced a neural network designed for recognizing handwritten digits. This network categorizes images into 10 different bins, each representing one of the digits.
What if we examine what happens within the neural network before it makes the final decision, such as "it's a '4'"? We can anticipate that the network internally holds numerical values that indicate an image is "mostly like a 4 but somewhat like a 2," and so on. The concept here is to extract these values and utilize them as elements in an embedding.
Here's the fundamental idea. Instead of directly characterizing "how close one image is to another," we identify a well-defined task, like digit recognition, for which we can obtain explicit training data. During this task, the neural network implicitly makes "closeness decisions" even if we never explicitly define "image proximity." We solely focus on the concrete task of identifying the represented digit in an image, and we let the neural network implicitly deduce what this implies about the "closeness of images."
To delve deeper into how this works for the digit recognition network, we can consider the network as comprising 11 successive layers, which can be conceptually summarized as follows (with activation functions displayed as distinct layers):

Initially, we input real images as 2D arrays of pixel values into the first layer. Eventually, from the final layer, we obtain an array of 10 values that essentially express the network's confidence regarding whether the image corresponds to any of the digits ranging from 0 to 9.
Feed in the image 4 and the values of the neurons in that last layer are:

To put it differently, at this stage, the neural net is extremely confident that the image represents the digit 4, and to obtain the output "4," we simply need to identify the neuron with the highest value.
Now, let's consider the step just before that. Right before the final operation in the network, there's a process called softmax, which aims to enhance certainty. However, prior to applying the softmax, the neuron values are as follows:

The neuron corresponding to "4" maintains the highest numerical value. Nevertheless, valuable information is also contained in the values of the remaining neurons. It's reasonable to assume that this array of numbers can, in a way, serve as a means to encapsulate the fundamental qualities of the image—thus offering us an embedding that can be utilized. As a result, each of the 4's in this array possesses a marginally distinct "profile" or "feature embedding," each of which is notably distinct from the 8's:

In this context, we are essentially employing 10 numbers to describe our images. However, it is often more advantageous to utilize a significantly larger number. For instance, in our digit recognition network, we can obtain a 500-element array by accessing the preceding layer. This array is likely a suitable choice for an "image embedding."
If we aim to create a visual representation of the "image space" for handwritten digits, we must "diminish the dimension," which involves projecting the 500-dimensional vector we have into, let's say, a 3D space:

We have discussed creating embeddings for images by training a neural network to identify which of many common objects an image depicts. This anchors the image embeddings in human-meaningful concepts like "cat" or "chair", while allowing the neural net behavior to generalize around that in a way that captures nuances of human perception.
We can take a similar approach to find useful embeddings for words. The key is to start with a word-related task that provides abundant training data. A common choice is word prediction - given the context "the ___ cat", what words best fill the blank? Based on a large text corpus, we can train a model to output probabilities for candidate words.
To formulate this as a numeric problem, we can assign each of 50,000 common English words a unique index number. So "the" becomes 914, "cat" is 3542, and so on. The model input is those numbers, and the output is a probability distribution over all possible words. Crucially, we can intercept the neural net's internal representations right before the output layer - these become our word embeddings.
Different embedding models (word2vec, GloVe, BERT, GPT, etc) produce vectors of hundreds to thousands of numbers for each word. In raw form these are opaque, but they capture semantic and syntactic relationships in a way that supports analogy tasks and other "human-judgement-like" behavior when words are embedded close together. So although cryptic, the embeddings derived from word prediction turn out to be useful and meaningful.

Previously we discussed how word embeddings allow us to represent words as vectors of numbers that capture semantic relationships. We can extend this idea to sequences of words, or even full blocks of text, by creating embedding vectors that summarize their meaning.
Inside ChatGPT, this is how it represents the conversation so far - by generating an embedding vector from the accumulated text. ChatGPT's goal is then to predict the next token (which could be a word or part of a word) based on this summary vector. It outputs a probability distribution over all possible next tokens.
Under the hood, ChatGPT uses a neural network architecture called a transformer to generate these text embeddings and make predictions. Transformers introduce the notion of "attention" - focusing more on certain parts of the text sequence. This is similar to how convolutional neural nets work for images, but more flexible.
The full ChatGPT model (based on GPT-3) has 175 billion weights, but follows the standard neural network pattern of successively transforming input vectors into output predictions through multiple layers. What makes it specialized for language is the transformer architecture.
ChatGPT operates in three main steps:
- Generate an embedding vector from the accumulated text
- Transform the embedding through multiple neural network layers
- Use the final representation to predict next token probabilities
Importantly, all parts of this pipeline are trained end-to-end, so the embeddings are optimized for the final prediction task. The network learns to represent and manipulate text in ways useful for generating coherent continuations.
While the high-level architecture is designed by humans, the specific behavior emerges entirely from training on vast amounts of text data. There are many intricate architectural details that reflect hard-won lessons in neural networks for NLP. But the key innovation is learning to embed and transform text in a way that captures semantics and allows generating reasonable synthetic text.
The initial component is the embedding module. Below is a simplified Wolfram Language representation of this module for GPT-2:

The embedding module starts with an input of n tokens, each represented by a unique integer ID between 1 and around 50,000. It embeds each token ID into a vector using a simple neural network layer. For GPT-2, these vectors are 768 dimensions, and for GPT-3 they are 12,288 dimensions.
In parallel, the positions of the tokens get embedded into separate vectors. Then the token value vectors and token position vectors are added together, element-wise, to give the final input embedding sequence.
The rationale for adding rather than concatenating or otherwise combining the vectors is empirical - this straightforward method works well in practice. Neural network design often involves trial-and-error, with the details emerging through training, not precisely engineered.
As an example, for the input "hello hello hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye bye", the embedding module would generate a sequence of embedding vectors incorporating both the meaning and position of each token.
While the high-level process is defined, the specific embeddings are learned based on what works best for the end task of generating text. The network learns how to map tokens to optimized vector representations.

The embedding vector for each token is displayed vertically, and horizontally, we can observe a series of "hello" embeddings, followed by a series of "bye" embeddings. The second array above represents the positional embedding, and its somewhat seemingly random structure is essentially the result of what was learned during training, particularly in the case of GPT-2.
Now, moving beyond the embedding module, we arrive at the central component of the transformer: a sequence of elements known as "attention blocks." GPT-2 employs 12 of these, while ChatGPT's GPT-3 utilizes 96. The inner workings of these attention blocks are intricate, akin to the complexities one encounters in large, challenging-to-comprehend engineering systems or even biological systems. Nevertheless, here is a simplified visual representation of a single "attention block" as implemented in GPT-2:

Each attention block contains a set of "attention heads," with GPT-2 employing 12 of them and ChatGPT's GPT-3 using 96. Each attention head independently processes various segments of values within the embedding vector. It's important to note that the specific rationale for dividing the embedding vector or the interpretation of its different parts remains unclear; this approach is simply a method that has proven effective through experimentation.
So, what exactly is the role of these attention heads? Essentially, they enable the model to "look back" into the sequence of tokens (i.e., the text generated so far) and encapsulate the past information in a manner that is valuable for predicting the next token. In the preceding section, we discussed using 2-gram probabilities to choose words based on their immediate predecessors. The "attention" mechanism in transformers extends this capability to allow attention to be paid to much earlier words, potentially capturing complex relationships, such as how verbs can reference nouns appearing many words earlier in a sentence.
In more precise terms, an attention head combines segments of embedding vectors associated with different tokens using specific weights. For example, the 12 attention heads in the initial attention block of GPT-2 exhibit specific patterns of "recombination weights" that encompass information from the entire sequence of tokens, as illustrated below for the "hello, bye" string:

Following the attention heads' processing, the resulting "re-weighted embedding vector" (which has a length of 768 for GPT-2 and 12,288 for ChatGPT's GPT-3) undergoes further processing through a conventional "fully connected" neural network layer. Understanding the exact operations performed by this layer can be challenging. However, a visualization is provided below, illustrating the 768x768 weight matrix it employs (in this case, for GPT-2).

When we calculate 64x64 moving averages, we start to observe the emergence of a structure that somewhat resembles a random walk.

What determines this structure? Ultimately, it's most likely a result of the neural network encoding various features of human language. However, at present, the specific nature of these features remains largely unknown. In essence, we're delving into the inner workings of ChatGPT (or at least GPT-2) and discovering that it's a complex system, and our understanding of it is limited, despite it ultimately generating human-readable language.
Now, after the initial pass through an attention block, we obtain a new embedding vector, which is then sequentially processed through multiple additional attention blocks (12 in the case of GPT-2 and 96 in GPT-3). Each attention block has its unique set of "attention" and "fully connected" weights. Below, you can see the sequence of attention weights for the input "hello, bye" for the first attention head in GPT-2.

And here are the (moving-averaged) “matrices” for the fully connected layers:

An interesting observation is that while the matrices of weights in different attention blocks visually appear quite similar, the distributions of the weight sizes can actually vary, and are not always Gaussian.

So, after traversing through all these attention blocks, what's the overall impact of the transformer? Essentially, it's about converting the initial collection of embeddings for the sequence of tokens into a final collection. In the case of ChatGPT, it chooses the last embedding in this collection and "decodes" it to generate a list of probabilities for the next token in the sequence.
This provides an overview of what's inside ChatGPT. It might seem complex, primarily due to the various engineering choices made, but at its core, it's based on simple elements. Essentially, it's a neural network composed of artificial neurons, each performing the basic task of taking numerical inputs and combining them with specific weights.
The original input for ChatGPT is an array of numbers, representing the embedding vectors for the tokens in the sequence. When ChatGPT operates to produce a new token, these numbers flow through the neural network layers. This process is strictly feedforward; there are no loops or backward movements.
This setup differs significantly from typical computational systems like Turing machines, where results are repeatedly reprocessed by the same computational elements. In ChatGPT, each computational element, or neuron, is used only once when generating a specific token.
However, there is still an "outer loop" of sorts in ChatGPT. When generating a new token, it considers the entire sequence of tokens that precede it, including those it generated itself. This creates an implicit "feedback loop," where each iteration is visible as a token in the generated text.
Now, let's delve into the core of ChatGPT: its neural network. At its essence, it's a collection of identical artificial neurons. While some parts of the network consist of fully connected layers where each neuron is connected to every neuron in the previous layer, ChatGPT, especially with its transformer architecture, has more structured sections. In these sections, specific neurons on different layers are connected, with some weights potentially being zero.
Additionally, certain aspects of ChatGPT's neural network don't neatly fit into homogeneous layers. For instance, within an attention block, there are areas where incoming data is duplicated, and each copy follows a different processing path, potentially involving a varying number of layers before recombination. While this representation helps understand the process, one could, in principle, envision densely filling in layers with certain weights being zero.
The longest path through ChatGPT involves around 400 core layers, which is not an excessively high number. However, there are millions of neurons in total, with 175 billion connections and weights. It's important to note that when ChatGPT generates a new token, it must perform calculations involving all of these weights. These calculations can be organized by layer, allowing for efficient parallel operations on GPUs. Nevertheless, for each generated token, approximately 175 billion calculations are needed, making it understandable why generating long pieces of text with ChatGPT can be time-consuming.
Despite the individual simplicity of these operations, the collective behavior of these neural elements manages to produce text that closely resembles human language. It's essential to emphasize that, at least to our current knowledge, there's no ultimate theoretical explanation for why this works. The fact that a neural network like ChatGPT can capture the essence of human language generation is, in itself, a surprising scientific discovery.
The Training of ChatGPT:
Now, let's shift our focus to how ChatGPT is trained. The neural network's 175 billion weights are the result of extensive training on a vast corpus of text derived from the web, books, and other sources created by humans. Despite having this training data, it's not obvious that a neural network can produce human-like text, and additional engineering is required to make it happen.
In the modern era, there's an abundance of human-written text available in digital form. The public web alone contains several billion human-written pages, with perhaps a trillion words of text. When considering non-public web pages, this number multiplies. Over 5 million digitized books, out of around 100 million published, offer another 100 billion words of text. This doesn't even account for text derived from speech in videos and other sources. Given the vast amount of data, training ChatGPT becomes a significant undertaking.
The number of training examples required to train a neural network for human language is not theoretically determined. In practice, ChatGPT was successfully trained on a few hundred billion words of text. Some text was presented multiple times during training, while others were shown only once. Despite the volume of training data, the neural network seemed to "learn what it needed" from the text.
The question arises: How large should the neural network be to learn the data effectively? There's no clear theoretical answer to this question either. It's essential to find a balance between the size of the network and the data it's trained on. ChatGPT demonstrates that a neural network with a few hundred billion weights can serve as a reasonable model for human-written text.
The interesting aspect is that the size of the neural network is comparable to the size of the training data. While it might seem that all the text data is somehow "stored" inside ChatGPT, in reality, it contains numerical representations that encode the structure of the training data. This representation requires approximately one neural net weight to carry the "information content" of a word of training data.
When ChatGPT generates text, it needs to utilize each weight just once. This means that for n weights, there are roughly n computational steps required. However, many of these steps can be performed in parallel on GPUs. Therefore, for each generated token, about n billion calculations are needed, which explains the time it takes to generate extensive text with ChatGPT.
In the end, the remarkable achievement is that these simple operations, when combined, can effectively mimic human-like text generation. There's no "ultimate theoretical reason" for why this works, but it demonstrates the power of neural networks in capturing the essence of human language.
Beyond Basic Training:
The majority of the effort in training ChatGPT is dedicated to exposing it to large amounts of existing text from various sources. However, there's another crucial part of the training process.
After the initial training from the original corpus of text, ChatGPT can start generating text on its own, responding to prompts, and more. The results might seem reasonable, but for longer text pieces, they can sometimes deviate into non-human-like territory. These deviations are not always apparent through traditional statistical analysis but are noticeable to human readers.
To address this, another step was introduced in ChatGPT's construction. Actual humans actively interact with ChatGPT, provide feedback on its output, and essentially teach it "how to be a good chatbot." Human raters assess ChatGPT's responses, and a prediction model is built to estimate these ratings. This prediction model can be applied as a loss function to the original network, allowing the network to be tuned based on the human feedback.
Interestingly, ChatGPT requires relatively little "poking" to guide it in particular directions. It doesn't need extensive retraining with weight adjustments to behave as if it's "learned something new." Often, simply telling ChatGPT something once as part of the prompt is sufficient for it to incorporate that information when generating text. This is a somewhat human-like quality, where ChatGPT can "remember" the information and use it for text generation. If the information is too bizarre or doesn't fit within its existing framework, it struggles to integrate it successfully.
Furthermore, ChatGPT can efficiently handle "shallow" rules and patterns in language, such as word associations and basic grammatical structures. However, it can't handle "deep" computations that involve many complex and potentially computationally irreducible steps. At each step, it processes data in a forward manner, without looping, except when generating new tokens.
When faced with problems that involve combinatorial complexity, neural networks need to reach out to actual computational tools for assistance. Wolfram|Alpha and Wolfram Language are well-suited for such tasks, as they are designed to discuss and compute things in the real world, similar to the capabilities of language-model neural networks.
What Really Lets ChatGPT Work?
Human language and the processes underlying language generation have always appeared highly complex. The human brain, with its relatively modest number of neurons (around 100 billion) and connections, has seemed an unlikely candidate to handle the complexity of language. Previously, it was possible to imagine that there might be some undiscovered layer of physics or complexity in the brain beyond its neural network.
However, ChatGPT provides a significant revelation. It demonstrates that an artificial neural network, with a comparable number of connections to the neurons in the human brain, can effectively generate human language. This suggests that there may not be a need for a new layer of physics or complexity in the brain to account for language processing.
The success of ChatGPT hints at the existence of fundamental "laws of language" and "laws of thought" waiting to be discovered. While these laws are currently implicit in ChatGPT's neural network, making them explicit could lead to more direct, efficient, and transparent language processing.
What might these laws of language and thought look like? They likely provide guidelines for how language and its components are structured. We will explore these potential laws in more detail in the following sections, using insights gained from examining the inner workings of ChatGPT and leveraging computational language capabilities.

ChatGPT lacks explicit "knowledge" of these rules, but during its training process, it appears to implicitly "uncover" and effectively adhere to them. How does this phenomenon occur? On a broader scale, the exact mechanism remains somewhat elusive. However, gaining insight into this process may be achieved by examining a simpler example.
Imagine a "language" constructed using sequences of open and close parentheses, denoted by ('s and )'s. This language possesses a grammar rule that dictates balanced parentheses, as illustrated by a parse tree like this:

Is it achievable to train a neural network to generate "grammatically correct" sequences of parentheses? There exist various approaches to manage sequences within neural networks, but let's opt for transformer networks, following ChatGPT's lead. Using a basic transformer network, we can commence the training process by providing it with grammatically accurate sequences of parentheses as training examples. A subtlety, which intriguingly parallels ChatGPT's generation of human language, involves the inclusion of an "End" token. This token indicates that the output should not extend any further—equivalent to reaching the "end of the story" in the context of ChatGPT.
If we configure a transformer network featuring just one attention block with 8 heads and feature vectors of length 128 (while noting that ChatGPT utilizes feature vectors of the same length but incorporates 96 attention blocks, each with 96 heads), it appears challenging to teach the network the intricacies of the parenthesis language. However, with 2 attention blocks, the learning process appears to reach convergence, particularly after presenting approximately 10 million training examples. Interestingly, supplying additional examples beyond this point tends to diminish the network's performance.
With this network configuration, we can replicate the procedure utilized by ChatGPT and request probabilities for the subsequent token in a parenthesis sequence:

In the first scenario, the network displays a high level of confidence that the sequence should not terminate at this point—a favorable outcome since an early ending would result in unbalanced parentheses. In the second case, the network accurately identifies that the sequence can come to an end at this stage. However, it also acknowledges the possibility of initiating a new sequence by introducing an open parenthesis, likely followed by a closing parenthesis. But here's a hiccup: even with its extensive training involving around 400,000 weights, the network suggests a 15% probability for the next token to be a closing parenthesis. This is not accurate, as such a choice would inevitably lead to unbalanced parentheses.
When we inquire about the network's most probable completions for increasingly longer sequences of open parentheses, we observe the following outcomes:

Indeed, up to a certain length, the network performs well, but it starts to falter beyond that point. This is a typical behavior often observed in precise scenarios involving neural networks or machine learning in general. Cases that a human can effortlessly solve with a glance are also within the capabilities of the neural network. However, when tasks require a more algorithmic approach (e.g., explicitly counting parentheses to ensure they are balanced), the neural network tends to struggle, seemingly lacking the computational depth required for reliable performance. It's worth noting that even the full current ChatGPT encounters challenges in accurately matching parentheses in lengthy sequences.
What does this imply for systems like ChatGPT and the syntax of a language like English? The language of parentheses is quite minimal and leans more towards an algorithmic approach. In contrast, English allows for more realistic predictions of grammatical correctness based on local word choices and contextual hints. The neural network excels at this, although it might occasionally miss some cases that are formally correct, which humans might also overlook. The key point is that the presence of an overall syntactic structure in language, with its inherent regularities, limits the extent to which the neural network needs to learn. An important observation, akin to natural science, is that the transformer architecture in neural networks, such as the one in ChatGPT, appears capable of learning the nested-tree-like syntactic structure that exists in all human languages, at least in some approximation.
Syntax represents one form of constraint on language, but there are additional considerations. For instance, a sentence like "Inquisitive electrons eat blue theories for fish" may be grammatically correct but is not something typically expected in conversation and would not be considered a successful output if generated by ChatGPT. This is because, with the standard meanings of the words used, the sentence lacks practical meaning.
Is there a universal way to determine if a sentence is meaningful? Traditionally, there is no comprehensive theory for this. However, ChatGPT seems to have implicitly developed a theory for this during its training, which involved exposure to billions of presumably meaningful sentences from the web and other sources.
What might this theory entail? There is a well-established area that offers some insight: logic. In particular, Aristotle's syllogistic logic provides a framework for distinguishing reasonable sentences from unreasonable ones based on specific patterns. For example, it is reasonable to assert "All X are Y. This is not Y, so it's not an X" (as in "All fishes are blue. This is not blue, so it's not a fish."). In a manner similar to Aristotle's development of syllogistic logic through rhetoric, one can envision that ChatGPT "discovered syllogistic logic" by analyzing vast amounts of text during its training. Consequently, ChatGPT is capable of generating text with "correct inferences" based on syllogistic logic, but it may struggle with more complex formal logic problems, for reasons similar to its challenges with matching parentheses.
However, beyond the specific example of logic, how can we systematically construct or recognize text that is deemed meaningful? While there are tools like Mad Libs that rely on predefined phrasal templates, ChatGPT seems to have a more general and implicit method to accomplish this. It's possible that this process is inherently tied to its vast number of 175 billion neural network weights, but there is reason to suspect that a simpler and more robust explanation may exist.
Meaning Space and Semantic Laws of MotionAs previously discussed, within ChatGPT, any piece of text is represented as an array of numbers, essentially serving as coordinates in a "linguistic feature space." Continuing a piece of text corresponds to tracing a trajectory in this linguistic feature space. The question arises: what defines or constrains the movement of points in this space while preserving "meaningfulness"? Could there be "semantic laws of motion" that govern this behavior?
To provide insight, consider how individual words, specifically common nouns, might be arranged within this feature space when projected into a 2D visualization:

We observed another instance of this concept earlier, using words related to plants and animals as an illustration. However, the common principle in both scenarios is that words with "similar semantic meanings" are positioned close to each other.
For another illustration, consider how words denoting distinct parts of speech are organized:

Certainly, a single word typically does not have a singular meaning and may not be limited to just one part of speech. Analyzing how sentences containing a word are positioned in feature space can help disentangle various meanings, as illustrated here with the word "crane" (referring to either a bird or a machine):

All right, it's reasonable to consider that this feature space arranges "words with similar meanings" in proximity. However, what additional structure can we discern within this space? Is there, for instance, a concept of "parallel transport" that indicates "flatness" in the space? One method to explore this is by examining analogies:

Certainly, even in 2D projections, there is often a subtle suggestion of flatness, although it's not consistently present.
Now, let's delve into trajectories. We can examine the path that a prompt takes in feature space for ChatGPT, and subsequently, we can observe how ChatGPT continues along that path:

There is certainly no "clear-cut geometric law" governing these motions, and this complexity should come as no surprise. We anticipate that this is a significantly intricate narrative. Furthermore, it's not evident what kind of embedding or variables would be the most natural choice to express a potential "semantic law of motion."
In the illustration above, we display several stages of the trajectory, where at each step, we select the word that ChatGPT deems the most probable (in a "zero temperature" scenario). However, we can also inquire about which words can potentially follow and with what probabilities at a given juncture:

In this scenario, we observe a "cluster" of high-probability words that appears to follow a relatively defined path in feature space. What occurs when we extend our analysis? The following are the consecutive "clusters" that emerge as we progress along the trajectory:

Here’s a 3D representation, going for a total of 40 steps:

Certainly, ChatGPT operates on a rather straightforward concept. It begins with a massive corpus of human-generated text collected from the web, books, and other sources. Then, a neural network is trained to generate text that resembles this dataset. This training equips it with the ability to take a "prompt" and continue it with text that mimics its training data.
The neural network architecture in ChatGPT is constructed from simple elements, albeit in large numbers, and its core operation involves processing input derived from the text it has generated so far. It proceeds word by word (or part of a word), without loops or other complexities, for each new segment it generates.
What's astonishing and somewhat unexpected is that this process can yield text that closely resembles what exists on the web, in books, and so forth. This text is coherent, human-like language, and it respects the context given in the prompt, incorporating information it has "learned" from its training dataset. While it doesn't always generate text that is globally coherent or logically sound (as it doesn't have access to computational tools), it produces text that sounds plausible based on its training data.
ChatGPT's specific design makes it highly convincing. However, until it can access external tools like Wolfram|Alpha, it's essentially extracting a coherent narrative from the statistics and conventional wisdom found in its training data. This uncovers an intriguing scientific insight: human language and the thought patterns behind it might be more structured and rule-like than previously believed. ChatGPT has stumbled upon this structure implicitly, but we have the potential to reveal it explicitly through semantic grammar, computational language, and related approaches.
ChatGPT's text generation is remarkably human-like, raising questions about its similarity to human brain operations. While its underlying artificial neural network architecture was inspired by a simplified model of the brain, the training strategy, hardware, and capabilities are quite distinct. The brain and computers have different hardware and computation mechanisms, and this disparity affects how ChatGPT learns and operates. Notably, ChatGPT lacks internal loops or the ability to recompute on data, which limits its computational capabilities compared to both the brain and conventional computers.
Enhancing ChatGPT to address these limitations without sacrificing training efficiency is a challenging task. However, such enhancements would make it more brain-like in its capabilities. Despite their strengths, brains have their own limitations, especially concerning irreducible computations. In such cases, both brains and systems like ChatGPT must rely on "external tools" like Wolfram Language to perform tasks beyond their inherent capabilities.
For now, it's exciting to witness what ChatGPT has achieved. It exemplifies the fundamental scientific principle that large numbers of simple computational elements can yield remarkable and unforeseen outcomes. Furthermore, it prompts us to revisit and better understand the fundamental nature and principles underlying human language and the thought processes that accompany it—a topic that has intrigued us for centuries.
The success of ChatGPT, despite its simplified architecture and the absence of explicit human-like cognition, underscores the rich structure and underlying regularities in human language. It suggests that language may be less chaotic and more rule-based than previously assumed. In a sense, ChatGPT acts as a fascinating bridge between the computational nature of language processing and the complexities of human communication.
One of the key takeaways from ChatGPT's accomplishments is that it exposes the substantial "computational underpinnings" of human language. While human language has evolved over millennia and encompasses cultural, social, and historical nuances, at its core, it operates based on rules and patterns that can be identified and described. These linguistic patterns can be thought of as "semantic laws of motion" that govern how words, concepts, and ideas can be combined to create meaningful and coherent language.
The concept of "semantic grammar" emerges as a significant field of study. Just as syntactic grammar provides rules for assembling words into sentences, semantic grammar offers rules for combining meaning in language. This semantic grammar delves into the finer gradations of language, addressing concepts and relationships that are less tangible but profoundly influential in language comprehension. It tackles questions like how ideas are connected and how meanings evolve as words are combined.
Semantic grammar also raises questions about the "model of the world" that underlies language. Every sentence implies a particular worldview and makes certain assumptions about the way things work. The challenge is to build a universal "model of the world" that can serve as the scaffolding for the diverse expressions of human language.
This is where computational language, a field that has been actively developed for decades, plays a crucial role. Computational language provides a systematic and symbolic representation of concepts and their relationships, akin to a "construction kit" for language and meaning. It offers a framework for expressing, dissecting, and reasoning about concepts, ultimately forming a bridge between human language and precise computational representation.
The future holds the promise of combining ChatGPT-like capabilities with comprehensive computational language to yield powerful language systems capable of more than just generating text. These systems can become tools for understanding, reasoning, and exploring the world around us. They can generate not only "locally meaningful text" but also "globally meaningful results." They can compute, inquire, assert, and create. In short, they can operate as engines for semantic understanding and expression.
While human language thrives on flexibility and is characterized by a degree of vagueness, computational language demands precision and clarity. It requires us to be explicit and rigorous in our descriptions, leaving no room for ambiguity. These qualities make computational language a potent framework for both understanding and generating language.
In conclusion, ChatGPT's success not only exemplifies the power of modern AI and deep learning but also propels us closer to understanding the fundamental principles that govern human language. It reveals that human language is built on semantic grammar, with rules and structures that underlie the generation of coherent and meaningful text. Through the synergy of AI-driven systems and computational language, we have the potential to create a new generation of tools that can unlock the true capabilities of human language, revolutionizing how we communicate, understand, and explore the world.


